Оптимизация скорости 1С:Предприятие 8.
ПО, гаджеты и железо 08 Май 2016 Надо сказать, при всей частоте возникновения вопроса «как ускорить работу 1С», мы с вами, всё же, имеем дело с одной из самых продуманных в этом плане платформ. Видал я творчество и на MS Access, и на самописных платформах, где слишком многое отдаётся на откуп разработчику и пришёл к выводу, что 1С:Предприятие, в плане оптимизации скорости предоставляет довольно разнообразные варианты.
Надо сказать, при всей частоте возникновения вопроса «как ускорить работу 1С», мы с вами, всё же, имеем дело с одной из самых продуманных в этом плане платформ. Видал я творчество и на MS Access, и на самописных платформах, где слишком многое отдаётся на откуп разработчику и пришёл к выводу, что 1С:Предприятие, в плане оптимизации скорости предоставляет довольно разнообразные варианты.
В прочем, обо всём по порядку. Далее, я поделюсь некоторым своим опытом в данном вопросе.
Почему тормозит 1С.
Что ж, у кого-то пользователи жалуются на медленное проведение какого-то часто используемого документа, иногда бывает, что медленно работают какие-то отдельные операции типа построения определённого отчёта или выполнения обмена данными. Где-то 1С «долго открывается», иногда долго обновляется. Проблемы могут быть постоянны или появляться с некоторой внезапностью.
В моей практике попадались разные причины недостаточной производительности 1С:Предприятие, и я могу выделить из них некоторые, не всегда очевидные, но достаточно частые.
- Локальная сеть. Самой частой причиной возникновения тормозов является появление второго, третьего и так далее пользователей, которые влекут за собой необходимость шаринга базы по сети. Есть уникальные сисадмины, которые прокидывают ЛВС через Wi-Fi для работы в 1С — при задержке доступа по Wi-Fi примерно в 10 раз больше, чем через проводную сеть, все обращения к базе замедляются в разы!
- Медленные диски. Система 1С:Предприятие, как и все СУБД, наиболее требовательна к дисковой подсистеме, чем программы другого назначения. Следовательно, организуя сервер для 1С:Предприятие нужно выбирать наиболее быструю и надёжную дисковую подсистему из доступных. Так же, по моим наблюдениям, HDD диски со временем начинают работать медленнее, возможно, вследствие износа магнитного слоя дисков. Это происходит примерно через 3-5 лет использования.
- Недостаток оперативной памяти. Вопрос, вроде бы, довольно легко диагностируется, и зачастую в первую очередь решается, но всё же о нём стоит упомянуть. Оперативная память решает. Если вам кажется, что надо её увеличить, то надо её увеличить. Более подробно о диагностике этого вопроса читайте ниже.
- Использование PostgreSQL на типовых настройках. Если вы имеете дело с клиент-серверным вариантом работы 1С:Предприятия, то, с большой вероятностью, вы используете PostgreSQL. Это очень популярная СУБД для такого режима работы платформы 1С, в виду того, что она бесплатная. Но, как и всё бесплатное, чтобы её правильно внедрить, надо немного поработать ручками и головой, в отличие от, может быть, той же Microsoft SQL Server. В последней танцев с бубном вокруг производительности, обычно, меньше. Ошибка заключается чаще всего в том, что установив PostgreSQL на сервер, специалист оставляет стандартный файл настроек postgresql.conf, который, как следует из документации, вообще не предназначен для постоянной работы и требует настройки под каждый конкретный сервер. Особенно, как я выяснил, это касается серверов на SSD-накопителях.
- Кривой код. Проблемы, которые таятся в неоптимальном использовании ресурсов, то же имеют место быть. Оптимизация запросов и программного кода таит в себе, зачастую, неограниченные возможности по ускорению работы в 1С.
Тестирование производительности сервера 1С.
Для диагностики производительности сервера обычно хватает штатных средств. Например, в Windows Server 2008 R2 есть замечательная кнопка «Монитор ресурсов» в диспетчере задач. С помощью монитора ресурсов можно достоверно произвести диагностику таких проблем как нехватка оперативной памяти или пропускной способности дисков.
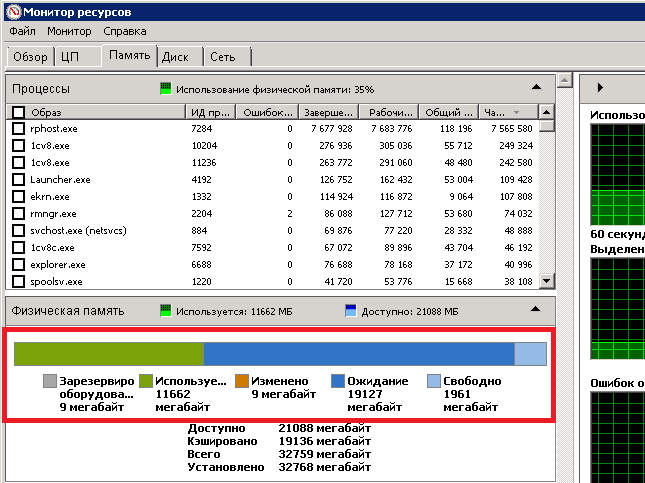 На странице «Память» можно оценить расход памяти теми или иными процессами, а так же наглядно оценить фактическую занятость оперативной памяти с помощью полоски внизу. Как вы заметите, помимо зелёной части полоски «Занято» есть не маловажная часть «Ожидание», которая отражает занятость памяти системным кешем. Наличие сектора «Свободно» означает, что памяти в данный момент хватает. Чем меньше памяти доступно для «Ожидания», тем меньше системный кэш, тем медленнее могут происходить некоторые операции. Тем не менее, я взял для себя ориентир, что примерно 30-40% памяти, находящийся в состоянии «Ожидание» и 60-70% в состоянии «Занято» это допустимый предел. Если памяти становится занято больше, то пора подумать либо об её очистке, либо об увеличении объёма памяти.
На странице «Память» можно оценить расход памяти теми или иными процессами, а так же наглядно оценить фактическую занятость оперативной памяти с помощью полоски внизу. Как вы заметите, помимо зелёной части полоски «Занято» есть не маловажная часть «Ожидание», которая отражает занятость памяти системным кешем. Наличие сектора «Свободно» означает, что памяти в данный момент хватает. Чем меньше памяти доступно для «Ожидания», тем меньше системный кэш, тем медленнее могут происходить некоторые операции. Тем не менее, я взял для себя ориентир, что примерно 30-40% памяти, находящийся в состоянии «Ожидание» и 60-70% в состоянии «Занято» это допустимый предел. Если памяти становится занято больше, то пора подумать либо об её очистке, либо об увеличении объёма памяти.
На странице «Диск» можно оценить загруженность дисковой подсистемы операциями ввода-вывода. В частности, если увидите, что очень много и часто происходит запись в файл «pagefile.sys», то это верный признак того, что памяти не хватает. Однако, надо иметь в виду, что как таковая активность на нём есть почти при любом количестве памяти из-за особенностей работы ОС. Но, пожалуй, главный показатель, который скажет вам о проблемах с дисковой системой, это 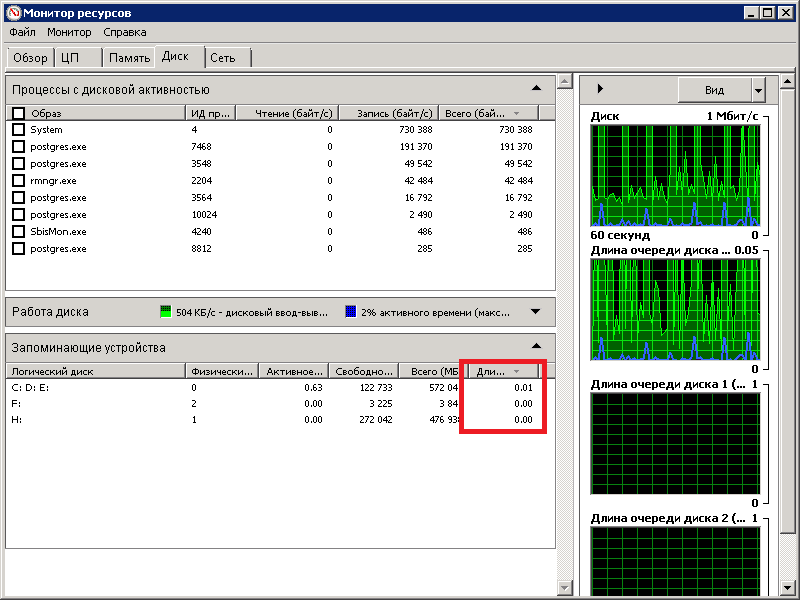 показатель «Длина очереди» в нижней части окна, где перечислены установленные диски. Если на одном из дисков этот показатель регулярно превышает значение 1, то это верный признак того, что этот диск не справляется с обработкой поступающих запросов. То есть, это говорит о том, что запросы отправляемые к диску чаще встают в очередь и ожидают завершения других запросов, чем обрабатываются сразу. В норме средняя очередь должна быть менее единицы, что говорит о том, что все операции чтения/записи отрабатываются вовремя, без ожидания других операций.
показатель «Длина очереди» в нижней части окна, где перечислены установленные диски. Если на одном из дисков этот показатель регулярно превышает значение 1, то это верный признак того, что этот диск не справляется с обработкой поступающих запросов. То есть, это говорит о том, что запросы отправляемые к диску чаще встают в очередь и ожидают завершения других запросов, чем обрабатываются сразу. В норме средняя очередь должна быть менее единицы, что говорит о том, что все операции чтения/записи отрабатываются вовремя, без ожидания других операций.
Это как в отделении СберБанка — если вы пришли, нажали кнопку на терминале и девушка, со странной интонацией в голосе, через громкоговоритель сразу пригласила вас к окну, то длина очереди оказалась меньше 1 и вы как-бы довольны. Если же вы приходите в своё отделение и регулярно ожидаете, когда обслужат бабулек перед вами, то длина очереди ожидания больше 1 и ваш запрос обрабатывается с задержкой.
Способы увеличения производительности работы с базой 1С.
Как это ни странно, но фирма «1С» буквально подарила нам (т. е. совсем бесплатно) предоставляет нам на платформе 8.3. простой клиент-серверный вариант работы, который способен основательно разгрузить локальную сеть, не прибегая к серьёзным затратам. Речь идёт о web-сервере.
Работа в режиме web-сервера, посредством тонкого клиента 1С:Предприятие позволяет перенести многие операции работы с данными действительно на сервер. В контексте сервера Apache или IIS запускается серверная часть 1С:Предприятие, которая обеспечивает доступ к файловой базе. Правда, в этом режиме, конечно же, не доступны разные плюшки, предоставляемые СУБД типа блокировок на уровне записей, кэширования, планирования запросов и т. п. но этот метод доступа сваливает различные операции прямого чтения данных на компьютер-сервер, за счёт чего значительно уменьшается сетевой трафик. Кроме этого, в режиме тонкого клиента, как я заметил, происходит оптимизация работы интерфейсных элементов, типа операций обновления списков, что позволяет так же разгрузить сеть. В случае необходимости, за счёт исчезновения некоторых приятных моментов типа подсказок при вводе, картинок и прочего, можно ещё больше улучшить отзывчивость клиентской части 1С — для этого надо включить галку «Низкая скорость соединения» при запуске базы 1С.
Как сделать публикацию базы 1С, настроить сервер и т. п. – тема выходящая за рамки статьи. Можете поискать информацию об этом сети. От себя скажу, что проще всего 1С взлетает на сервере Apache, но вот гнаться за последней его версией не стоит — смотрите информацию о совместимости на сайте 1С.
 Вернёмся к варианту работы с СУБД PostgreSQL. Так уж случилось, что те базы, которые сопровождает наша компания «крутятся» на SSD-дисках. Приход PostgreSQL зачастую был связан не столько с погоней за производительностью, сколько за вообще техническими ограничениями вроде допустимого размера таблиц базы данных.
Вернёмся к варианту работы с СУБД PostgreSQL. Так уж случилось, что те базы, которые сопровождает наша компания «крутятся» на SSD-дисках. Приход PostgreSQL зачастую был связан не столько с погоней за производительностью, сколько за вообще техническими ограничениями вроде допустимого размера таблиц базы данных.
После поднятия базы данных на Postgres, нужно обязательно покрутить настройки postgresql.conf. Какие-то достоверные рекомендации дать сложно, многое познаётся опытным путём, могу лишь описать некоторые настройки этого файла, которые давали какой-то, а иногда и очень ощутимый прирост производительности (или его падение).
Хороший прирост дало изменение параметра wal_sync_method: wal_sync_method = open_datasync. Этот параметр задаёт метод работы с файловой системой. В значении open_datasync под Windows появилось некоторое ускорение работы.
Стоит подобрать оптимальное значение для checkpoint_segments. Этот параметр задаёт частоту полной синхронизации страниц памяти с базой на накопителе. Слишком мало — даст частую запись, слишком много — в случае сбоя может не сохранить часть данных. По крайней мере, так я понял работу этого параметра.. При проблемах с долгим проведением закрытия месяца в Бухгалтерии предприятия 3.0, я проверил варианты от 3 (по умолчанию) до 96 , и где -то от 32 разницы не было. Оставил 64 с некоторым запасом, т.к. при работе всех пользователей, этот параметр мог бы потребовать изменений:
checkpoint_segments = 64
Однако, наибольший эффект в этих экспериментах дали параметры из раздела Planner Cost Constants. С их помощью удалось добиться почти трёхкратного роста производительности.
Параметры seq_page_cost и random_page_cost задают абстрактную цену соответственно последовательного и случайного доступа к страницам базы данных на накопителе. Стоит обратить внимание, что на SSD накопителях эти параметры имеют меньшую разницу, чем на HDD, т.к на SSD случайная выборка данных занимает почти столько же времени, как и последовательная. А вот на HDD накопителе цена случайного доступа к данным (random_page_cost) гораздо больше, чем последовательного. Подробнее о параметре random_page_cost можно прочитать тут (на английском, так что Google-переводчик в помощь).
Две последних настройки нужно рассматривать в совокупности с параметрами cpu_tuple_cost, cpu_index_tuple_cost и cpu_operator_cost. Они задают цену операций процессора, когда оптимизатору предстоит решить выбирать ли нагрузку на процессор, или же предпочесть нагрузку на диск в некоторых операциях.
У меня по по разделу «Planner Cost Constraints» получился такой «прайс-лист»:
seq_page_cost = 1
random_page_cost = 1.5
cpu_tuple_cost = 0.001
cpu_index_tuple_cost = 0.0005
cpu_operator_cost = 0.00025
Рекомендую, так же, почитать про параметры работы с памятью effective_cache_size, shared_buffers, work_mem и поэкспериментировать с ними. На больших выборках данных и при большом количестве пользователей их неправильная настройка должна привести к плохим результатам. А правильная — к хорошим.
Интересный случай настройки PosgreSQL произошёл при поднятии на нём одной из старых релизов Управление торговлей 10.3. Путём временного отключения параметра enable_nestloop, удалось улучшить выполнение некоторых сложных запросов. Совсем отключать этот параметр не рекомендуется, т. к. в более простых запросах операции соединения таблиц могут наоборот выполняться медленнее. Что интересно, включив его через некоторое время, случилось чудо — производительность осталась на том же уровне. Я это связываю с тем, что планировщику пришлось использовать другие методы соединения таблиц и накопить по ним статистику. В результате, после возвращения настроек, планировщик уже «знал что делать» с теми проблемными запросами, погоняв их другими методами, вроде indexscan или bitmapscan, и больше не использовал на них метод nestloop.
 На любом варианте работы с базой данных — будь то web-сервер, СУБД или файловый вариант, я очень рекомендую перебороть в себе консерватизм и страх перед… в общем-то, уже не такой уж и новизной. Простая замена ваших HDD, на SSD-накопители закроет большинство ваших проблем. Правда, не стоит рассчитывать, что при прямом доступе к файловой базе данных по локальной сети это даст какой-то серьёзный эффект. Если только ваши HDD не на столько медленные, что даже задержка запросов по сети отрабатывает быстрее… Что вряд ли.
На любом варианте работы с базой данных — будь то web-сервер, СУБД или файловый вариант, я очень рекомендую перебороть в себе консерватизм и страх перед… в общем-то, уже не такой уж и новизной. Простая замена ваших HDD, на SSD-накопители закроет большинство ваших проблем. Правда, не стоит рассчитывать, что при прямом доступе к файловой базе данных по локальной сети это даст какой-то серьёзный эффект. Если только ваши HDD не на столько медленные, что даже задержка запросов по сети отрабатывает быстрее… Что вряд ли.
Для пущей уверенности, настройте регулярное копирование базы данных средствами Windows с твердотельника на жёсткий диск. Благо, встроенная система архивации данных Windows позволяет быстро делать инкрементальные архивы внутри одной машины. Это должно немного расслабить вас в отношении «небольшого ресурса» SSD-накопителей. А так же, при наличии бюджета, настройте массив RAID1 для зеркальной записи на SSD, на случай чего. Комбинация двух этих методов должна снять с вас всё бремя ответственности за внедрение продвинутых технологий, которые ещё не обкатаны десятилетиями…
 Не стоит забывать (а вы о нём наверняка помните) о таком устаревающем методе, как установка терминал-серверной ОС и запуск работы в терминальном режиме. Способ, в общем-то очевиден, по этому на нём останавливаться не буду. Стоит сказать, что при всей своей кажущейся простоте он не является панацеей, довольно сложен и дорог. Но, тем не менее, терминалка находится в топе способов оптимизации производительности. Хотя, как мне кажется, эта штука устаревает с развитием интернета, сетей и технологий доступа к данным, с годами отходя на второй план, оставаясь лишь у консервативно настроенных сисадминов.
Не стоит забывать (а вы о нём наверняка помните) о таком устаревающем методе, как установка терминал-серверной ОС и запуск работы в терминальном режиме. Способ, в общем-то очевиден, по этому на нём останавливаться не буду. Стоит сказать, что при всей своей кажущейся простоте он не является панацеей, довольно сложен и дорог. Но, тем не менее, терминалка находится в топе способов оптимизации производительности. Хотя, как мне кажется, эта штука устаревает с развитием интернета, сетей и технологий доступа к данным, с годами отходя на второй план, оставаясь лишь у консервативно настроенных сисадминов.
Некоторые вопросы оптимизации кода и запросов в 1С.
Все описанные выше способы хороши, но криво написанный код, отчёт или запрос, который выбирает избыточное количество данных, да ещё и которые потом блокируются для записи могут свести на нет все ваши попытки улучшить положение.
Например, в упоминавшейся выше УТ 10.3 на критичном участке — загрузка данных в оффлайн-ККМ проходила очень медленно, — история кончилась лишь тогда, когда были переписаны несколько процедур. В частности, ранее неплохо работавшая в файловом режиме обработка, создавала множественные обращения к базе данных, для получения значения «Уровень()» у элемента справочника. Однако, при переводе в клиент-сервер этот метод, выполнявшийся десятки тысяч раз за один запуск обработки, создавал наибольшую загруженность. Пришлось отдельной процедуркой пройти все группы справочника, которые обычно составляют 1-5% от всего количества элементов, сложить эти группы в таблицу значений и рассчитать для них уровень заблаговременно. За тем, вместо метода «Уровень()» был сделан поиск по этой таблице значений как по кэшу, что ускорило работу обработки с 40 минут до 4-х, т.е. в 10 раз.
Подобные неявные обращения к базе данных возможны при обращении к свойствам ссылок или при получении представления объектов — нужно иметь это ввиду. Если вам нужно вывести представление объекта, получите в запросе заблаговременно функцией ПРЕДСТАВЛЕНИЕССЫЛКИ(). Если вам нужно обратиться к свойству ПометкаУдаления элемента справочника во время обхода запроса, получите его в запросе, а не обращайтесь к нему через Ссылка.ПометкаУдаления. А ещё лучше, сразу в запросе ограничьте выборку элементов, например «ГДЕ НЕ Номенклатура.ПометкаУдаления». Но, в общем, во мне сейчас говорит Капитан Очевидность, он же напоминает вам и про параметры виртуальных таблиц, которые иногда не используют новички, в которых тоже можно сразу ограничить выборку данных. Принцип Бритвы Оккама «Не стоит творить сущности без необходимости» — один из главных методов написания оптимального кода. Нужно на максимально ранних этапах отрезать ненужные данные.
Встроенный замер производительности в Конфигураторе вам в помощь. В нём вы сможете отследить подобные неочевидные ошибки.
А вот менее бросается в глаза такой метод, как использование индексов во временных таблицах запроса. Вообще, времена вложенных запросов давно прошли, и практически все таблицы, которые выбираются как вложенный запрос имеет смысл выносить во временную таблицу. А эти временные таблицы, если по их полям происходят соединения, сортировки или отборы имеет смысл индексировать.
Например:
ВЫБРАТЬ
НоменклатураБезПометок.Наименование,
Остатки.Остаток
ИЗ
(Выбрать Номенклатура.Ссылка ИЗ Номенклатура ГДЕ НЕ Номенклатура.Пометка) Как НоменклатураБезПометок
ЛЕВОЕСОЕДИНЕНИЕ
РегистрыНакопления.Остатки(&КонецПериода) Как Остатки
ПО Остатки.Номенклатура = НоменклатураБезПометок.Ссылка
Быстрее будет работать так (добавляем индекс и временную таблицу):
ВЫБРАТЬ
Номенклатура.Наименование,
Номенклатура.Ссылка
ПОМЕСТИТЬ втНоменклатураБезПометок
ИНДЕКСИРОВАТЬ ПО Номенклатура.Ссылка
;
ВЫБРАТЬ
НоменклатураБезПометок.Наименование,
Остатки.Остаток
ИЗ
втНоменклатураБезПометок Как НоменклатураБезПометок
ЛЕВОЕСОЕДИНЕНИЕ
РегистрыНакопления.Остатки(&КонецПериода) Как Остатки
ПО Остатки.Номенклатура = НоменклатураБезПометок.Ссылка
А ещё быстрее — так (сразу убираем лишнее на этапе выборки остатков):
ВЫБРАТЬ
Остатки.Номенклатура.Наименование КАК Наименование,
Остатки.Остаток
ИЗ
РегистрыНакопления.Остатки(&КонецПериода, НЕ Номенклатура.Пометка) Как Остатки
Однако, стоит без фанатизма относиться к индексам. Во-первых, построение индекса занимает время — на запросах с маленьким количеством записей построение индекса может свести на нет выигрыш от выполнения запроса. Во-вторых, индексы строятся в оперативной памяти вашего сервера, что тоже надо иметь в виду. Но всё же, на больших выборках данных, обрабатываемых в запросе, индексы могут стать спасением.
Надеюсь, что эта статья навела вас на идеи о том, как решить проблемы со скоростью доступа к базе 1С. Если вам понравилась статья, поделитесь ею на своей странице в ВКонтакте или расскажите о ней в своём блоге или на форуме.
Напоследок, почитайте нашу статью о том, как защитить ваши базы от вирусов-шифровальщиков или о том как второй монитор может облегчить вашу трудовую жизнь.
Свежие комментарии